

Double Special: Is there finally parity in college hoops?
Exploring final unbeatens and variation between top teams using R

What a crazy week in college hoops: Nos. 1, 2, 3, and 5 all lost to unranked teams — and #2 Houston, the country’s last unbeaten, fell to an unranked Iowa State at Hilton Coliseum in Ames.
Houston’s loss prompted a thought: We’re just two months into the season, and no perfect teams remain. How does that compare to past years? Are we seeing more parity at the top of the sport? It feels like we don’t have a truly “elite” team.
Today’s Buckets & Bytes is a two-part special — double the graphs for double the fun!
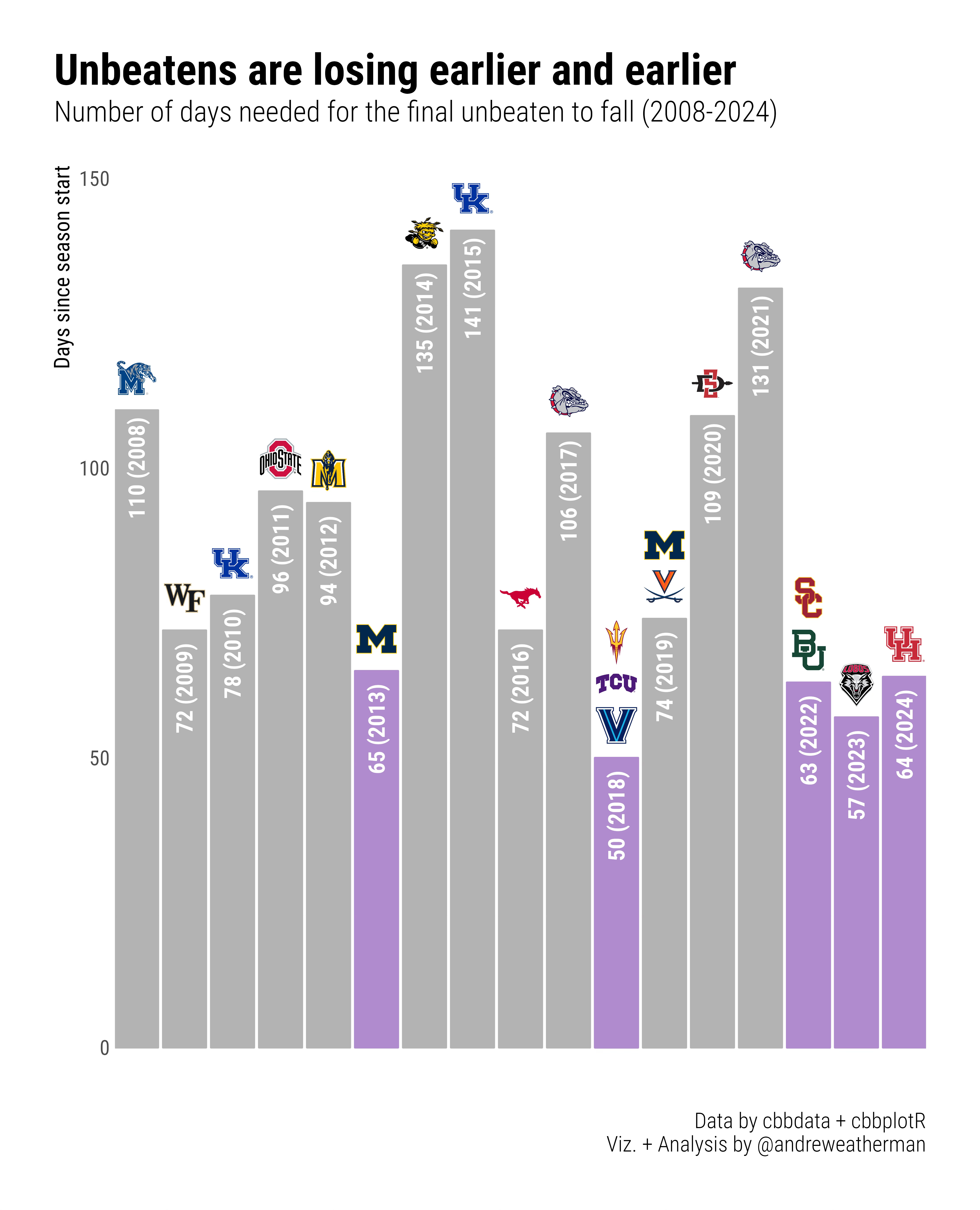
First, we’ll be taking a look at the former: When has the last unbeaten fallen in each season back to 2008? We’ll be using {dplyr} to isolate the last unbeaten and calculate how many days they lasted.
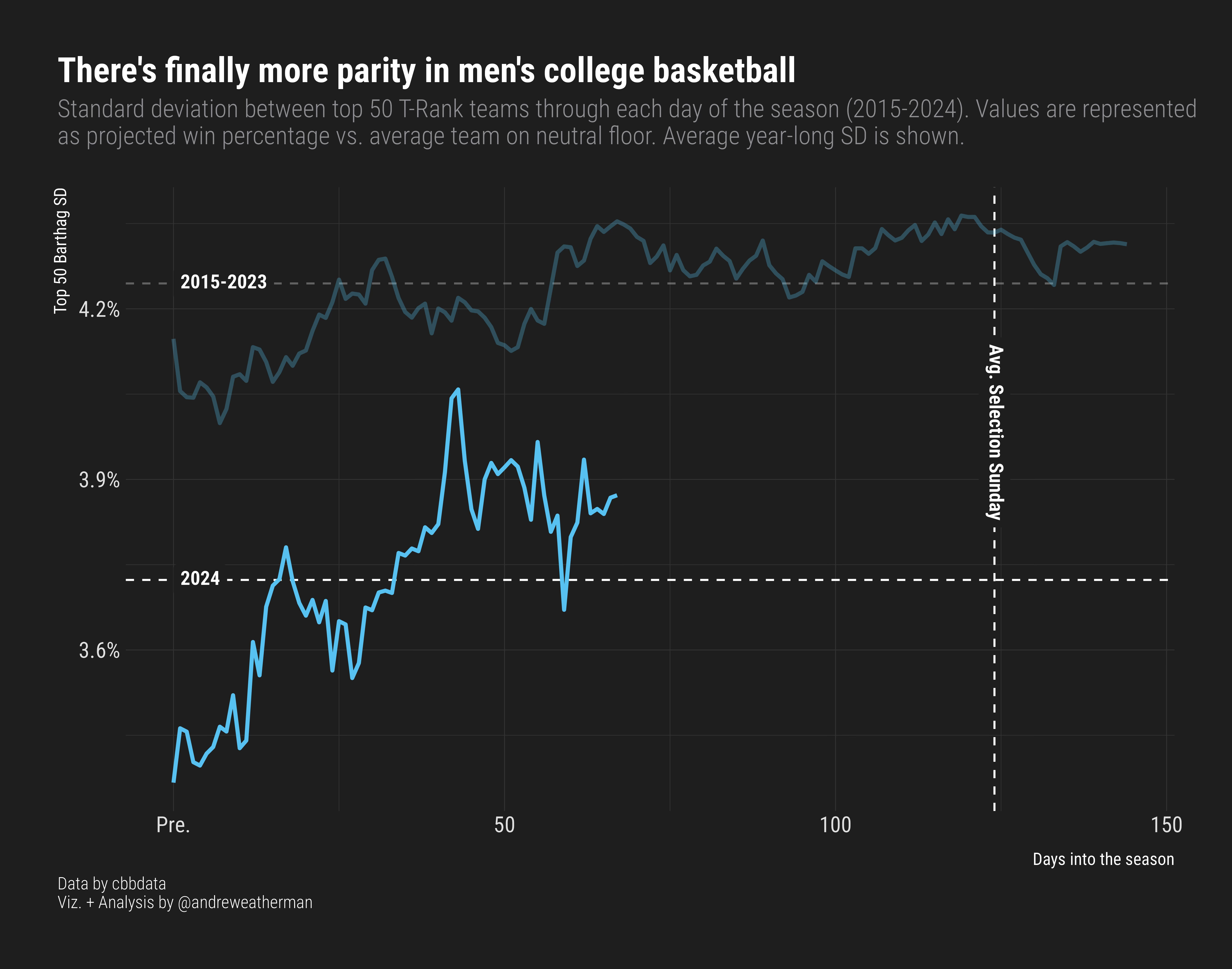
Next, we’ll use historical T-Rank data (2015-Present) from {cbbdata} to investigate per-day rating variation between top teams as a quick litmus test for hoops parity.
Before we start, let’s load all necessary libraries.
As a reminder: This tutorial will use the {cbbdata} package, and you must register for a free API key.
pkgs <- c('cbbdata', 'cbbplotR', 'tidyverse', 'ggtext', 'hrbrthemes', 'glue')
invisible(lapply(pkgs, library, character.only = TRUE))Part 1: Unbeaten Bar Chart
Getting the data
To create the unbeaten bar chart, we need to calculate when the last perfect record fell relative to the start of the season. To do this, we first use {cbbdata} to pull game results.
Game results
Remember, we want to calculate how many days after the start of the season that the last unbeaten fell — so we are using first to select the earliest observed date in each year (i.e. the start of the season).
R allows for operations on date classes, and we can take advantage of this by subtracting game date from start date (first day of each season) to quickly calculate the number of days between the two.
game_results <- cbd_torvik_game_box() %>%
filter(team %in% cbd_teams()$common_team) %>%
arrange(date) %>%
mutate(start_date = first(date),
days_diff = date - start_date,
.by = year)When did the last unbeaten fall?
Now that we have our game results, we need to calculate when each team lost their first game. We can do this by combining a few summarize logical statements. First, we calculate cumulative team losses, then we decide whether that team is still unbeaten (i.e. cum_loss is 0), and finally we pull the date associated with the first observation of is_unbeaten being “no.”
If you’re relatively new to R, pay careful attention to how we are counting observations inside a column where a query is true. A lot of beginners, and I did this too, will create a binary variable for game results, 0 or 1, and sum those to calculate wins. But you don’t need to do that! Instead, you can simply do sum(result == “W”) to count the number of rows where a team won a game. Simple things like this will help in writing clean, concise code.
game_results <- game_results %>%
summarize(
cum_loss = cumsum(result == 'L'),
is_unbeaten = ifelse(cum_loss == 0, 'yes', 'no'),
first_loss = first(date[which(is_unbeaten == 'no')]),
days_diff = first(days_diff[which(is_unbeaten == 'no')]),
.by = c(team, year)
) %>%
slice_max(days_diff, n = 1, by = year) %>%
distinct(year, team, days_diff)Stacking logos with custom vjust + fill colors
There are a few seasons where multiple teams ended as the last one standing. To address this, we are going to create a vjust column so that our logos can “stack” on top of one another (if multiple teams are present).
We can do this with a case_when statement and some simple logic. The dimensions of the USC logo are a bit different, for whatever reason, so we’re handling that specific year by separating our logic statements. Feel free to play around with these numbers, if you’d like, but these are the baselines that I found to work best with this plot.
We are grouping by year, evident through .by = year, so n() and row_number() refer to the total count and position in the group, respectively. This is a convenient way to avoid needing to create more variables to accomplish the same task.
game_results <- game_results %>%
mutate(vjust = case_when(n() == 1 ~ 0.465,
!team %in% c('Baylor', 'USC') &
n() > 1 ~ 0.51 - (row_number() * 0.045),
team == 'Baylor' ~ 0.465,
team == 'USC' ~ 0.408),
.by = year)Fill color
Finally, we want to highlight years in which the last unbeaten fell within 65 days of the season tip. We are going to use another mutate call to assign one of two colors based on the days_diff value. I like this magenta color, but feel free to switch either one.
game_results <- game_results %>%
mutate(fill = ifelse(days_diff <= 65, '#B08CCF', 'grey70'))Plotting the data
That’s all of the data that we need! {dplyr} provides some powerful tools for making data analysis intuitive and quick. Let’s throw it over to {ggplot2} and {cbbplotR}.
Coloring and filling with strings
Sometimes you might have columns with either color names (e.g., “red”) or hex strings, as we do above, but when you try to color or fill based on those columns, you’ll notice that the colors default to red and blue! The scale_X_identity family of functions allow you to map pre-scaled values directly — in this case, color names or hex strings.
To handle this, we must use scale_fill_identity and scale_color_identity while referencing our fill column inside the aes argument. To not interfere with the fill and color of team logos, it’s vital that your fill and color aes only appear in geom_col. By default, every geom will inherit any aes placed inside the initial ggplot() function.
If you are unsure about what this means, please reference the code below, or — better yet — experiment with placing the fill and color aes in different places to see what happens (you won’t break anything).
Expanding axes
When you make a standard plot, you might notice that the points do not “hug” the y-axis, meaning that there is some separation between the first plotted observation and the y-axis. Normally, this space is fine and lets the plot “breathe,” but sometimes it looks a bit funky. I think the latter applies in our case, and to remove that separation, we need to use the expand argument inside scale_x_continuous. You can see how this works below, and again, I encourage you to play around with the values to see how the graph responds.
Panel grid redundancy
A point of clarification: I don’t believe that a panel grid is appropriate for our visualization. To remove them, you would typically place panel.grid = element_blank() inside a theme call. However, there is a peculiarity with the {hrbrthemes} package, which we are using here, where doing so does not remove them. Instead, you need to individually set the major and minor grid lines to be blank. If you are following along and notice the former redundancy, just understand that this package is requiring us to separate those lines (shrugs).
game_results %>%
ggplot(aes(year, days_diff, team = team)) +
geom_col(aes(fill = fill, color = fill), position = "identity") +
geom_cbb_teams(aes(vjust = vjust), width = 0.055) +
scale_fill_identity() +
scale_color_identity() +
scale_y_continuous(limits = c(0, 145)) +
scale_x_continuous(expand = c(0,0)) +
geom_text(
aes(label = glue("{days_diff} ({year})")),
angle = 90, color = 'white', nudge_y = -10,
family = 'Roboto Condensed', fontface = 'bold',
size = 4.5
) +
theme_ipsum_rc() +
theme(plot.title.position = 'plot',
plot.subtitle = element_text(vjust = 2.8, size = 16),
plot.title = element_text(size = 24),
plot.caption = element_text(size = 12),
axis.text.x = element_blank(),
axis.title.y = element_text(size = 12),
panel.grid.minor = element_blank(),
panel.grid.major = element_blank()) +
labs(title = 'Unbeatens are losing earlier and earlier',
subtitle = 'Number of days needed for the final unbeaten to fall (2008-2024)',
caption = 'Data by cbbdata + cbbplotR\nViz. + Analysis by @andreweatherman',
x = NULL, y = 'Days since season start')Part 2: Rating Variation Line Plot
Getting the data
For the variation line chart, we only need one piece of data: T-Rank archive ratings. If you have authorized your {cbbdata} account with KenPom, feel free to swap this data with KenPom ratings (accessed with cbd_kenpom_ratings_archive) for a more complete look (three extra seasons available). For the purpose of this blog, however, we are going to use the freely available T-Rank archive ratings.
Archive ratings
This graph doesn’t require much data; the focus is more on plotting techniques. In fact, we can grab all necessary data with just a few lines.
To avoid making two separate data frames, we can create a year_group variable that we will group by to calculate standard deviations. We can also add a column for an alpha value, which will help us in distinguishing our groups when plotting.
As useful as performing operations on dates can be, as illustrated by the previous plot, you do need to coerce them to a numeric before you are able to filter.
You might notice that we add a day to each date: T-Rank archive ratings are day-end, which means that, e.g., the final ratings on November 6, 2023 are also the ratings on the morning of November 7, 2023. It follows that this step isn’t logically needed for our plot, of course, but it’s a good idea to get into the practice of doing this with T-Rank data, especially if you are later adding on games, e.g., so that everything is on the same time scale.
plot_data <- cbd_torvik_ratings_archive() %>%
mutate(date = date + 1,
start = first(date),
days_diff = date - start,
year_group = ifelse(year == 2024, 'current', 'past'),
.by = year) %>%
filter(rank <= 50 & between(as.numeric(days_diff), 0, 144)) %>%
summarize(top_sd = sd(barthag),
.by = c(days_diff, year_group)) %>%
mutate(alpha_group = ifelse(year_group == 'current', 1, 0.35))Annotation data
Our plot is going to have some brief annotations, and instead of using three separate geoms for labeling, we can create a quick data frame that can be passed through to take advantage of the principles of aes in {ggplot2}.
label_data <- data.frame(
label = c('Avg. Selection Sunday', '2015-2023', '2024'),
x = c(124, 0, 0),
y = c(0.0415, mean(filter(plot_data, year_group == 'past')$top_sd),
mean(filter(plot_data, year_group == 'current')$top_sd)),
angle = c(270, 0, 0)
)Plotting the data
This plot is a tad more complex than our first one, but there aren’t too many more moving parts. Again, if you’re confused about what particular functions do in the code, I recommend iterating over each line to experiment with what changes when you add or remove certain things. The best way to learn is by doing.
What’s that tilde doing (data = ~ …)?
In our geom_mean_lines functions, you might notice that we are doing some weird looking thing → data = ~ filter(.x, …). As briefly mentioned earlier, each geom “inherits” all data and aesthetic calls, but we want to plot average lines for both year groups. We could create a new data frame that includes the average values, but that feels unnecessary: After all, our data is there but we just need to find a way to intuitively access it.
Enter: the tilde (~). The tilde operator is allowing us to essentially “pass through” the data object being inherited, i.e., plot_data, to a filter function that queries by year_group. The .x is a “placeholder” for that inherited data; if you’ve used across or {purrr}, you’ll quickly recognize it.
plot_data %>%
ggplot(aes(days_diff, top_sd)) +
geom_mean_lines(data = ~ filter(.x, year_group == 'past'),
aes(y0 = top_sd), alpha = .3, color = 'white') +
geom_mean_lines(data = ~ filter(.x, year_group == 'current'),
aes(y0 = top_sd), color = 'white') +
geom_vline(xintercept = 124, color = 'white', linetype = 'dashed') +
geom_line(linewidth = 1, aes(group = year_group,
alpha = alpha_group)) +
geom_richtext(data = label_data,
aes(x, y, label = label, angle = angle),
family = 'Roboto Condensed', fontface = 'bold',
text.color = 'white', hjust = 0, label.color = NA,
fill = '#1e1e1e', size = 3.6) +
scale_alpha_identity() +
scale_y_continuous(labels = scales::label_percent()) +
scale_x_continuous(labels = c('Pre.', '50', '100', '150')) +
hrbrthemes::theme_modern_rc() +
theme(legend.position = 'none',
plot.title.position = 'plot',
plot.subtitle = element_text(vjust = 2.7),
plot.caption.position = 'plot',
plot.caption = element_text(hjust = 0),
axis.title.x = element_text(vjust = -2),
axis.title.y = element_text(vjust = 2)) +
labs(title = "There's finally more parity in men's college basketball",
subtitle = 'Standard deviation between top 50 T-Rank teams through each day of the season (2015-2024). Values are represented\nas projected win percentage vs. average team on neutral floor. Average year-long SD is shown.',
x = 'Days into the season',
y = 'Top 50 Barthag SD',
caption = 'Data by cbbdata\nViz. + Analysis by @andreweatherman') Full Code
Plot 1: Bar Chart
Getting the data
game_results <- cbd_torvik_game_box() %>%
# ensure we only account for D-1 teams
filter(team %in% cbd_teams()$common_team) %>%
arrange(date) %>%
mutate(start_date = first(date),
days_diff = date - start_date,
.by = year) %>%
summarize(
cum_loss = cumsum(result == 'L'),
is_unbeaten = ifelse(cum_loss == 0, 'yes', 'no'),
first_loss = first(date[which(is_unbeaten == 'no')]),
days_diff = first(days_diff[which(is_unbeaten == 'no')]),
.by = c(team, year)
) %>%
slice_max(days_diff, n = 1, by = year) %>%
distinct(year, team, days_diff) %>%
mutate(vjust = case_when(n() == 1 ~ 0.465,
!team %in% c('Baylor', 'USC') &
n() > 1 ~ 0.51 - (row_number() * 0.045),
team == 'Baylor' ~ 0.465,
team == 'USC' ~ 0.408),
fill = ifelse(days_diff <= 65, '#B08CCF', 'grey70'),
.by = year)Plotting
game_results %>%
ggplot(aes(year, days_diff, team = team)) +
geom_col(aes(fill = fill, color = fill), position = "identity") +
geom_cbb_teams(aes(vjust = vjust), width = 0.055) +
scale_fill_identity() +
scale_color_identity() +
scale_y_continuous(limits = c(0, 145)) +
scale_x_continuous(expand = c(0,0)) +
geom_text(
aes(label = glue("{days_diff} ({year})")),
angle = 90, color = 'white', nudge_y = -10,
family = 'Roboto Condensed', fontface = 'bold',
size = 4.5
) +
theme_ipsum_rc() +
theme(plot.title.position = 'plot',
plot.subtitle = element_text(vjust = 2.8, size = 16),
plot.title = element_text(size = 24),
plot.caption = element_text(size = 12),
axis.text.x = element_blank(),
axis.title.y = element_text(size = 12),
panel.grid.minor = element_blank(),
panel.grid.major = element_blank()) +
labs(title = 'Unbeatens are losing earlier and earlier',
subtitle = 'Number of days needed for the final unbeaten to fall (2008-2024)',
caption = 'Data by cbbdata + cbbplotR\nViz. + Analysis by @andreweatherman',
x = NULL, y = 'Days since season start')Saving
ggsave(plot = last_plot(), 'last_unbeaten.png', dpi = 600, bg = 'white', w = 7.54, h = 9.31)Plot 2: Line Chart
Getting the data
plot_data <- cbd_torvik_ratings_archive() %>%
mutate(date = date + 1,
start = first(date),
days_diff = date - start,
year_group = ifelse(year == 2024, 'current', 'past'),
.by = year) %>%
filter(rank <= 50 & between(as.numeric(days_diff), 0, 144)) %>%
summarize(top_sd = sd(barthag),
.by = c(days_diff, year_group)) %>%
mutate(alpha_group = ifelse(year_group == 'current', 1, 0.3))label_data <- data.frame(
label = c('Avg. Selection Sunday', '2015-2023', '2024'),
x = c(124, 0, 0),
y = c(0.0415, mean(filter(plot_data, year_group == 'past')$top_sd),
mean(filter(plot_data, year_group == 'current')$top_sd)),
angle = c(270, 0, 0)
)Plotting
plot_data %>%
ggplot(aes(days_diff, top_sd)) +
geom_mean_lines(data = ~ filter(.x, year_group == 'past'),
aes(y0 = top_sd), alpha = .3, color = 'white') +
geom_mean_lines(data = ~ filter(.x, year_group == 'current'),
aes(y0 = top_sd), color = 'white') +
geom_vline(xintercept = 124, color = 'white', linetype = 'dashed') +
geom_line(linewidth = 1, aes(group = year_group,
alpha = alpha_group)) +
geom_richtext(data = label_data,
aes(x, y, label = label, angle = angle),
family = 'Roboto Condensed', fontface = 'bold',
text.color = 'white', hjust = 0, label.color = NA,
fill = '#1e1e1e', size = 3.6) +
scale_alpha_identity() +
scale_y_continuous(labels = scales::label_percent()) +
scale_x_continuous(labels = c('Pre.', '50', '100', '150')) +
hrbrthemes::theme_modern_rc() +
theme(legend.position = 'none',
plot.title.position = 'plot',
plot.subtitle = element_text(vjust = 2.7),
plot.caption.position = 'plot',
plot.caption = element_text(hjust = 0),
axis.title.x = element_text(vjust = -2),
axis.title.y = element_text(vjust = 2)) +
labs(title = "There's finally more parity in men's college basketball",
subtitle = 'Standard deviation between top 50 T-Rank teams through each day of the season (2015-2024). Values are represented\nas projected win percentage vs. average team on neutral floor. Average year-long SD is shown.',
x = 'Days into the season',
y = 'Top 50 Barthag SD',
caption = 'Data by cbbdata\nViz. + Analysis by @andreweatherman')Saving
ggsave(plot = last_plot(), w = 8.9, h = 7, 'parity_trank.png', dpi = 600)If you found this walkthrough and code useful, please consider subscribing below and sharing the post! It helps me a ton.